La vision
Détecter les couleurs de notre cube permet au robot de résoudre un cube en autonomie.
Le processus de détection est constitué de plusieurs étapes :
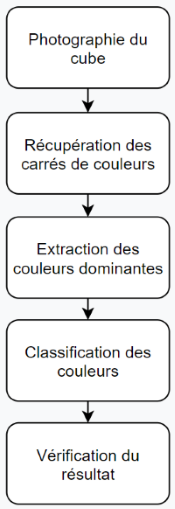
Le processus de détection de couleurs
Chacune des étapes de ce processus est détaillée dans cet article.
Photographie du cube et récupération des carrés de couleur
Les images prises par la caméra sont récupérées et manipulées à l’aide de OpenCV (ici).
Dans le cas du robot d’OTVINTA, il y aura deux photos de prises pour chaque face, puisque le robot tient à chaque fois le cube avec deux mains, cachant ainsi deux couleurs à chaque fois.
Pour chacune des photos que nous prenons, nous allons extraire les zones de l’image correspondant aux étiquettes du cube.
L’objectif sera désormais d’interpréter ces 54 carrés de couleurs.
Voici un exemple de données extraites sur un cube :

Les carrés de couleurs extraits des images
Sur cette image, chaque ligne correspond à une face du Rubik’s Cube, et on peut constater que certaines zones noires ont parfois été incluses (il s’agit du plastique noir constituant le cube).
Ces informations sont exploitables, puisqu’un humain serait capable de reconstituer le cube sans grande difficulté. (Il est possible de faire une nette distinction entre les couleurs)
Extraction des couleurs dominantes
Une première étape pour interpréter ces images est de réussir à extraire la couleur dominante sur chacun de ces carrés de couleurs. Pour cela, on utilise un algorithme de Clusterisation de type K-Means, avant de récupérer la couleur correspondant au cluster le plus grand.
Voici le résultat lorsqu’on applique cette procédure sur les mêmes données montrées plus haut :

Les couleurs dominantes extraites de chaque carrés
Le résultat est satisfaisant : les couleurs correspondent bien à l’image précédente, et pourront par la suite être exploitées afin de réaliser une classification.
Classification des couleurs
Méthode de classification n°1 - Le centre le plus proche
Il s’agit ici d’une méthode de classification simple.
Elle exploite un avantage que nous possédons vis-à-vis du contexte : nous connaissons déjà la couleur du centre de chaque face (puisque ces centres sont immobiles sur un Rubik’s cube). Le centre de la face BLANCHE est BLANC, le centre de la face ORANGE est ORANGE, etc.
Sur ce visuel, les centres sont présents sur la quatrième colonne :

Le centre de chaque face est sur la colonne du milieu.
Afin de classifier les carrés de couleur de cette image, nous pouvons donc nous demander, pour chacun d’entre eux, « de quel centre sa couleur est-elle la plus proche ? ».
Pour examiner le degré de similarité entre deux couleurs, il est très pratique de les considérer sous un format LAB.
Le format LAB décrit l’aspect d’une couleur pour les yeux humains. Il possède trois composantes :
- La luminosité (L) comprise entre 0 et 100.
- La composante a (axe vert-rouge), comprise entre -128 et 127.
- La composante b (axe bleu-jaune), comprise entre -128 et 127.
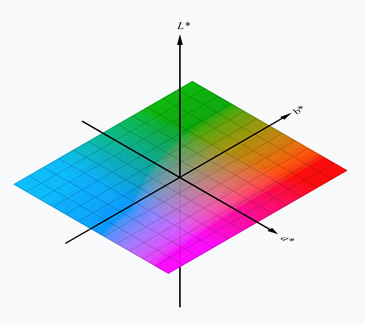
Le format de couleur LAB
Sous ce format, il est possible d’évaluer la similarité entre deux couleurs grâce à la géométrie Euclidienne. (Il s’agit de la distance entre deux points)
Ainsi, nous pouvons associer chaque couleur dominante à la couleur du centre le plus proche, et terminer notre classification.
Méthode de classification n°2 - Réseau de neurones
Afin de classifier nos couleurs, il est possible d’utiliser un réseau de neurones. Nous allons examiner chacune de nos couleurs indépendamment, avec éventuellement un paramètre représentant les conditions d’éclairage.
En effet, les conditions d’éclairage peuvent changer grandement l’aspect d’une couleur. On peut ainsi facilement confondre du jaune / blanc, ou du rouge / orange.
Création d’un dataset
Un réseau de neurones se base sur l’expérience précédemment acquise pour classifier de nouveaux éléments.
Pour représenter cette expérience, nous allons enregistrer les couleurs que nous percevons avec notre caméra. Nous pourrons ensuite utiliser ces enregistrements pour créer un modèle adapté à notre problème.
Pour effectuer ces enregistrements, nous pouvons demander au robot de photographier chacune des faces d’un cube résolu à répétition. Les couleurs dominantes sont ensuite enregistrées dans des fichiers csv.
Analyse des données enregistrées
Après avoir fait quelques enregistrements dans des conditions d’éclairage différentes, il peut être intéressant de visualiser nos données, afin de mieux cerner le problème.
Le graphique suivant présente 12 000 enregistrements dans un graphique au format LAB (cliquer pour agrandir):
Les enregistrements de couleurs affichés sur un graphique LAB
Eh bien, il s’agit d’un graphique intéressant !
En l’observant, on peut comprendre les difficultés que nous pouvons rencontrer :
- Le rouge et l’orange se superposent. En d’autres termes, une même couleur peut être rouge ou orange, selon les conditions d’éclairage.
- La valeur du blanc varie également beaucoup avec les conditions d’éclairage. Il peut donc facilement se confondre avec d’autres couleurs (principalement avec le jaune).
- Plus une couleur est lumineuse, moins elle est saturée. (A l’exception du vert, qui ne se rapproche pas de (a = 0, b = 0) lorsque la luminosité augmente)
Mais tout de même, les données sont bien regroupées. Il devrait donc être possible de faire une classification, et ce même avec une luminosité assez faible puisque la valeur de la couleur détectée (a et b) semble cohérente avec le reste du cluster dans ces conditions.
Pour réussir à différencier le rouge et l’orange, nous pouvons rajouter une nouvelle information à nos enregistrements. Pour que cela soit efficace, il faut que cette donnée soit représentative des conditions d’éclairage.
Une idée est d’utiliser la valeur enregistrée pour du blanc lors de chaque enregistrement. (Chaque série de photographie commence par une photo de la face blanche, dont le centre est toujours blanc).
Nos enregistrements comprennent donc six valeurs : Les trois premières correspondent à la valeur du blanc enregistré sur la première face, et les trois dernières correspondent à la couleur que nous tentons de classifier.
Création d’un modèle de classification
Bien, maintenant que nous possédons toutes les données dont nous avons besoin et que nous les avons analysées, il est temps de construire un modèle de classification !
Pour ce faire, nous allons utiliser TensorFlow et Python. (La création d’un tel modèle est beaucoup plus simple en Python qu’en Kotlin)
Les données sont extraites des différents fichiers .csv, puis le dataset est séparé dans un dataset d’entraînement, et un dataset de validation.
Un modèle Keras est créé grâce à TensorFlow, son architecture est la suivante :
- Un input de 6 valeurs (LAB de la couleur que nous cherchons à classifier, LAB de la couleur blanche)
- Couche intermédiaire de 64 neurones.
- Couche intermédiaire de 32 neurones.
- Couche intermédiaire de 32 neurones.
- Couche intermédiaire de 32 neurones.
- L’output du réseau : 6 activations correspondant à la probabilité estimée d’appartenir à une catégorie.
Voici les courbes d’apprentissage sur 10 epochs :
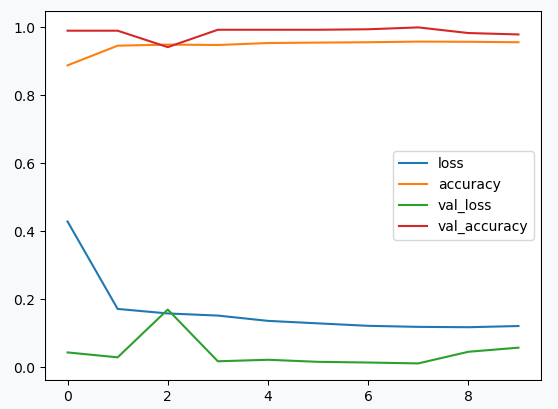
Les courbes d’apprentissage du modèle
Nous avons une précision proche de 99% sur le dataset de validation, ce qui est satisfaisant. Ce modèle semble bien se généraliser (pas d’overfitting) et nous pouvons donc nous attendre à avoir de bons résultats avec !
Le modèle ainsi entraîné est enregistré, et il sera désormais possible de l’exploiter depuis le code Kotlin.
Utilisation du modèle Keras depuis Kotlin
Il est possible d’importer un modèle Keras depuis du code Kotlin grâce à la librairie Deeplearning4j.
Une fois le modèle importé, il ne reste plus qu’à l’interroger avec les différentes couleurs que nous devons classifier : les valeurs d’activation des nœuds de sortie nous renseigneront sur la probabilité d’appartenir à une catégorie.
Vérification du résultat
Maintenant que nous avons :
- Photographié le cube
- Récupéré les carrés de couleur
- Extrait la couleur dominante de ces carrés
- Classifié ces couleurs
Il faut vérifier que les données obtenues sont cohérentes (il peut y avoir des erreurs de classification).
Pour ce faire, nous allons initialiser un cube avec les couleurs que nous avons obtenues, et regarder si ce cube est valide. (Nous allons “vérifier l’intégrité” du cube)
Un Rubik’s Cube doit obligatoirement satisfaire l’ensemble des conditions suivantes :
- Il existe neuf carrés de chaque couleur.
- Chaque pièce existe, et n’existe qu’une fois.
- Le nombre d’arêtes bien orientées est pair.
- La somme des valeurs des orientations des coins est multiple de trois.
- La parité du nombre de permutations d’arêtes nécessaire à la résolution des arêtes est égale à la parité du nombre de permutations de coins nécessaires à la résolution des coins.
Si ces conditions sont validées, notre initialisation de cube est terminée, et nous pouvons débuter une résolution ! Le cube est forcément faisable.
Axes d’amélioration
Il est bien sûr possible de rajouter d’autres méthodes de classifications, mais pour le moment, le plus grand problème au niveau de l’expérience utilisateur est que si nous n’arrivons pas à un cube valide à la fin du processus, il faut tout recommencer et prendre de nouvelles photos.
Pour éviter cela, nous pourrions examiner le résultat de la détection et déterminer la cause la plus probable de l’échec.
1. Trouver les erreurs de classification
Si une seule couleur a été mal détectée, il devrait être possible de trouver laquelle.
En effet, si nous avons détecté 8 carrés rouges et 10 carrés orange, ça signifie très probablement qu’un des carrés orange était en fait rouge.
En examinant la liste des pièces de cube issue de notre détection de couleurs, nous pouvons présenter à l’utilisateur une hypothèse sur l’état du cube le plus probable.
2. Vérifier si la détection correspond à un cube invalide
Si vous démontez un Rubik’s Cube et que vous le remontez aléatoirement, il est possible qu’il ne puisse pas être résolu. Si c’est le cas, le cube ne pourra pas passer la vérification d’intégrité, et ce même si les couleurs ont bien été détectées.
Nous pouvons présenter à l’utilisateur une hypothèse sur l’état du cube, et si elle est valide le renseigner sur la démarche à suivre pour corriger le problème.
3. Examiner les conditions d’éclairage
Il peut arriver que des reflets empêchent de voir les carrés de couleurs sur les images, ou alors que l’image soit trop sombre.
Cela peut être détecté en examinant les luminosités moyennes des couleurs, et en constatant qu’il y a de nombreuses erreurs de classification.
Auquel cas, nous pourrions l’indiquer à l’utilisateur, et l’inviter à ajuster les conditions d’éclairage.